7 Claude Skills for Researchers That Handle the Workflow, Not Just the Writing
The best Agent Skills for researchers — scientific problem selection, bioinformatics pipelines, single-cell RNA analysis, data science, and more. Works with Claude Code.

New cluster. New environment. Three hours to figure out why a Nextflow pipeline that ran cleanly on the last system is failing on this one — before you’ve touched the data. Then an hour to run QC on the new single-cell dataset, another hour to get the scVI environment configured correctly, and somewhere in there the biological question you were actually trying to answer has been pushed to tomorrow.
Computational biology’s dirty secret isn’t that the science is hard. It’s that the infrastructure layer between the science is relentless and mostly underdocumented. Agent Skills are built for that layer — structured, repeatable computational workflows that Claude handles consistently so you can focus on the science. Install a skill once and Claude runs that workflow the same way every time: the same QC parameters, the same pipeline flags, the same data conversion conventions — without you having to re-specify the setup from scratch each session.
The seven skills below are built from Anthropic’s official bio research plugins, with one data science skill added for analytical depth. They’re designed for life sciences researchers and bioinformaticians working in Python-based computational environments, and they work best with Claude Code where direct file access and shell execution make the computational workflows actually executable.
The skills
1. Bio Research Scientific Problem Selection
Choosing what to work on is the highest-leverage decision in research, and the one that gets the least structured attention. Most scientists evaluate new project ideas informally — through conversation, intuition, and a rough mental model of feasibility and impact. A structured framework surfaces the considerations that tend to get missed in that informal process.
The Bio Research Scientific Problem Selection skill gives Claude a structured approach to research problem evaluation: assessing project feasibility, novelty, and potential impact against a consistent framework, identifying the key risks that could derail the project, pressure-testing the scientific rationale, and comparing competing project ideas when you’re deciding where to invest research time.
Use it when evaluating a new project idea before committing significant resources, when deciding what to work on next across a set of competing options, or when a project has stalled and you need a structured framework for diagnosing whether it’s worth continuing.
npx skills add anthropics/knowledge-work-plugins --skill bio-research2. Bio Research Start
Starting a new research project in a new computational environment — whether that’s a fresh HPC allocation, a new collaborator’s cluster, or a new cloud instance — involves a predictable set of setup steps that take longer than they should. Tool discovery, environment configuration, dependency management, and getting the first workflow running are all straightforward in principle and tedious in practice.
The Bio Research Start skill gives Claude a structured approach to getting a new research workflow off the ground: environment setup for the specific computational context, tool discovery and installation, dependency resolution, and the initial configuration checks that confirm the environment is ready before you commit to a long pipeline run.
Use it at the start of a new project, when onboarding into a new computational environment you haven’t worked in before, or when setting up a fresh instance for a pipeline that needs to run in a clean environment.
npx skills add anthropics/knowledge-work-plugins --skill bio-research3. Bio Research Single Cell RNA QC
Single-cell RNA-seq QC is methodologically well-established but computationally specific. The scverse ecosystem has standardised best practices — MAD-based filtering, doublet detection, ambient RNA correction — but implementing them correctly and consistently across different datasets requires knowing which parameters to set and why, and producing the visualisations that make QC decisions defensible.
The Bio Research Single Cell RNA QC skill gives Claude a structured approach to QC on single-cell RNA-seq data: loading .h5ad or .h5 files, computing per-cell quality metrics (nCounts, nGenes, percent mitochondrial), applying MAD-based adaptive thresholds for filtering low-quality cells, running doublet detection, and generating the QC visualisations (violin plots, scatter plots, distribution histograms) that document the filtering decisions.
Use it when you need to assess data quality before downstream analysis, when applying consistent QC standards across a multi-sample dataset, or when following scverse/scanpy best practices is required for publication or reproducibility.
npx skills add anthropics/knowledge-work-plugins --skill bio-research4. Bio Research Nextflow Development
Running nf-core pipelines correctly requires knowing the right pipeline version, the correct parameter flags for your data type, how to handle input samplesheets, and how to configure execution for your compute environment. Getting it wrong wastes compute time and produces results you can’t trust.
The Bio Research Nextflow Development skill gives Claude a structured approach to running nf-core bioinformatics pipelines: rnaseq, sarek, and atacseq on local FASTQs or public datasets from GEO/SRA. It covers pipeline configuration for your compute environment, samplesheet generation, the key parameters that affect output quality, and the post-run checks that confirm the pipeline completed correctly.
Triggers on nf-core, Nextflow, FASTQ analysis, variant calling, gene expression analysis, or GEO/SRA accession numbers. Most useful for researchers who run nf-core pipelines periodically rather than daily — often enough that getting it right matters, infrequently enough that the parameter choices aren’t memorised.
npx skills add anthropics/knowledge-work-plugins --skill bio-research5. Bio Research scVI Tools
Variational autoencoder-based methods for single-cell analysis — scVI, scANVI, PeakVI, totalVI, MultiVI — offer substantial advantages over classical dimensionality reduction for batch correction, multi-modal integration, and reference mapping. They’re also more complex to configure and interpret correctly than PCA-based workflows.
The Bio Research scVI Tools skill gives Claude a structured approach to deep learning-based single-cell analysis: data integration and batch correction with scVI and scANVI, ATAC-seq analysis with PeakVI, CITE-seq multi-modal integration with totalVI, and multiome analysis with MultiVI. It covers model configuration, training, latent space interpretation, and the downstream analyses that build on the learned representations.
Use it for variational autoencoder-based dimensionality reduction, batch correction across datasets from different protocols or batches, multi-modal data integration, or reference mapping when you have a well-characterised reference atlas to map new data onto.
npx skills add anthropics/knowledge-work-plugins --skill bio-research6. Bio Research Instrument Data to Allotrope
Laboratory instrument outputs are a Tower of Babel: each instrument produces its own proprietary format — PDFs, CSVs, Excel files, TXT outputs — that requires custom parsing before it can be used in downstream systems. Standardising to a common format is the prerequisite for aggregating data across instruments, labs, or studies.
The Bio Research Instrument Data to Allotrope skill gives Claude a structured approach to converting laboratory instrument output files to the Allotrope Simple Model (ASM) JSON format or a flattened 2D CSV: parsing the instrument-specific format, mapping fields to the Allotrope schema, handling missing or ambiguous fields, and validating the output against the target schema.
Use it when standardising instrument data for a LIMS system, when building a data pipeline that ingests data from multiple instrument types, or when an analysis workflow requires data from instruments with incompatible native formats.
npx skills add anthropics/knowledge-work-plugins --skill bio-research7. Senior Data Scientist
Analytical decisions in research — which statistical model to use, how to design an experiment to be statistically interpretable, how to handle confounders, whether an observed effect is real or an artefact — benefit from the same kind of structured expert review as the biological questions. Most researchers make these decisions informally, without a framework.
The Senior Data Scientist skill gives Claude a structured senior data science perspective on analytical problems: statistical modelling approach selection, experimental design review, ML model design for biological data, experiment planning for statistical power, and insight extraction from complex analytical outputs.
Use it when working through a modelling decision that isn’t obvious (which model family, which regularisation approach, how to handle class imbalance), when designing an experiment and you want a structured assessment of whether it will be statistically interpretable, or when reviewing an analysis approach before presenting results to collaborators or in a paper.
npx skills add alirezarezvani/claude-skills --skill engineering/senior-data-scientistHow these skills chain together
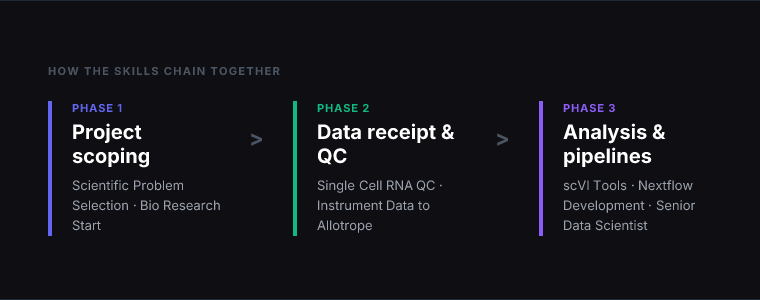
Here’s how these skills map to a typical single-cell RNA-seq project from data receipt to analysis.
Project scoping: Use Scientific Problem Selection before committing to a new direction — especially useful when deciding between competing analytical approaches or experimental designs.
Environment setup: Use Bio Research Start when setting up the computational environment for the project on a new cluster or instance.
Data receipt: Use Single Cell RNA QC as the first step after receiving new data — before any downstream analysis. Run the QC, review the visualisations, and document the filtering decisions.
Dimensionality reduction and integration: Use scVI Tools for batch correction and integration if the dataset spans multiple batches or modalities.
Pipeline runs: Use Nextflow Development for any bulk sequencing data (RNA-seq, ATAC-seq, variant calling) that feeds into the single-cell analysis.
Instrument data: Use Instrument Data to Allotrope when lab instrument outputs need to be standardised before entering the analysis pipeline.
Statistical review: Use Senior Data Scientist when making modelling decisions or designing experiments that require statistical rigour.
Want the full set?
Two stacks are built for research workflows:
- The Bio Research Stack — single-cell RNA QC, scVI tools, Nextflow pipelines, scientific problem selection, and instrument data conversion
- The Data Science & Analytics Stack — statistical analysis, SQL, data exploration, visualisation, validation, dashboard building, and ML experiment design
How to install
Browse all research skills → /audiences/researchers
📬 Weekly digest
Get the best new skills every Tuesday
3–5 hand-picked skills. Free forever.
More guides
April 4, 2026 · 8 min read
The CEO of Y Combinator Ships 10,000 Lines of Code a Day. Here's Exactly How.
Garry Tan runs one of the most demanding jobs in tech. He's also shipping more code than ever. gstack — his open-source Claude Code system — is how. Here's what it is and why it works.
March 25, 2026 · 7 min read
How to Create a Claude Skill (Step-by-Step Guide)
Learn how to build, test, and share your own Claude Code skills. A complete walkthrough — from blank file to installed skill — with real examples and best practices.
March 24, 2026 · 8 min read
Awesome Claude Skills: The Complete Searchable List (2026)
Every major Claude Code skills list and awesome-claude-code repository in one place — with install commands, categories, and a searchable directory for all 370+ skills.